As I write this, all Google search results are being flagged as malware and redirected to a scary warning page, including google.com itself:

The warning page (which I’ve only seen a handful of times before today) looks like this:
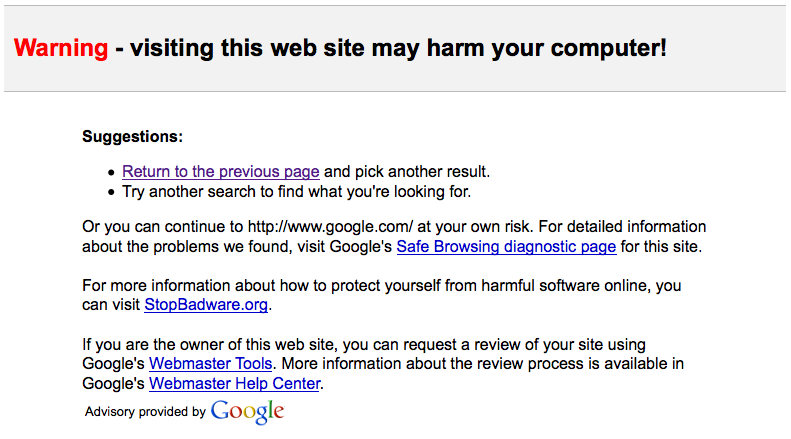
Note the absence of any links to the offending site (in this case http://www.google.com/), diverting traffic to StopBadware.org (which is unsurprisingly down) and its own Safe Browsing diagnostic page , which is also down:

Looking forward to seeing the explanation for this… sucks to be whoever was responsible right now. When was the last time Google was effectively down for over half an hour?
Update: So it’s definitely not just me – twitter’s going crazy too.
Update 2: It’s on Slashdot now, but hard to say if mainstream press has picked it up because Google News is down now too:

Update 3: StopBadware.org are pointing the finger at Google for their denial of service (see “Google glitch causes confusion“).
Update 4: Google are pointing the finger back at StopBadware.org (see “This site may harm your computer” on every search result?!?!). Marissa Mayer has explained on the official blog the cause of the problem to have been human error in that “the URL of ‘/’ was mistakenly checked in as a value to the file and ‘/’ expands to all URLs“.
Update 5: StopBadware.org claim that Google’s explanation (above) “is not accurate. Google generates its own list of badware URLs, and no data that we generate is supposed to affect the warnings in Google’s search listings. We are attempting to work with Google to clarify their statement.“
Update 6: Google statement updated, noting that they “maintain a list of such sites through both manual and automated methods” and that they work with StopBadware.org to “come up with criteria for maintaining this list, and to provide simple processes for webmasters to remove their site from the list“, not for delivery of the list itself.
Summary: Now everything’s back to normal the question to ask is how it was possible that a single character error in an update to a single file could disable Internet searches for the best part of an hour for most users? StopBadware.orgGoogle should never have allowed this update to issue (even though each case needs to be individually researched by humans the list itself should be maintained by computers) and Google’s servers should never have accepted the catch-all ‘/’ (any regexp matching more than a single server should be considered bogus and ignored). Fortunately it’s not likely to happen again, if only because Google (who are “very sorry for the inconvenience caused to [their] users”) are busy putting “more robust file checks in place”.
Moral of the story: Wherever black or white-listing is implemented there are more moving parts and more to go wrong. In this case the offending service provides a tangible benefit (protecting users from malware) but those of you whose leaders are asking for your permission to decide what you can and can’t see on the Internet should take heed – is the spectre of censorship and the risk of a national Internet outage really worth the perceived benefit? Will such an outage be rectified within an hour as it was by Google’s army of SREs (Site Reliability Engineers)? And perhaps most importantly, will the scope of the list remain confined to that under which it was approved (typically the ‘war on everything’ from child pornography to terrorism) or will it end up being used for more nefarious purposes? In my opinion the benefit rarely outweighs the (potential) cost.